
Svarta lådor och hallucinationer
Varför en maskininlärningsmodell ger ett visst svar kan vara mer eller mindre svårt att förstå. Komplexitet och mängden parametrar som algoritmerna nyttjar blir även i relativt små modeller snabbt omöjliga att överblicka eller förstå. Men det finns en rad verktyg att ta till för att undersöka hur modeller fungerar. För Evidens är att detta helt fundamentalt eftersom transparens och möjlighet att förklara orsak och verkan, kausalitet, nästan alltid är lika värdefullt som de analysresultat vi levererar. Efterfrågans storlek, priset, är lika viktigt som varför efterfrågan är på denna nivå.
En del metoder för att göra algoritmer mer transparenta är modellagnostiska, vilket betyder att de kan tillämpas oavsett typ av algoritm. Andra metoder är specifika för en viss sorts algoritmer och kräver ofta mer ingående förståelse för hur algoritmen fungerar för att enkelt beskrivas. Därför nöjer vi oss här med att översiktligt beskriva två modellagnostiska metoder.
Permutational importance
En första fråga att söka svar på är vilken betydelse olika variabler har för att förklara modellens resultat. En förhållandevis enkel metod är att analyser permutational importance. Antag att en regression görs med en maskininlärningsmodell där pris predikteras med elva variabler.
Första steget är att undersöka om modellen förklarar priset rimligt väl. Maskininlärningsmodeller utvärderar man helst på en delmängd av datasetet som modellen inte har tillgång till när den tränas, ett så kallat testdataset (detta görs ännu bättre med cross-validation). För testdatasetet kan modellens prediktiva förmåga undersökas genom beräkning av exempelvis R2 eller medelabsolutfel (mean absolut error, mae). Nästa steg är att slumpvis blanda alla rader för en våra indatavariabler. Därefter tränar vi på nytt modellen på vårt träningsdataset och beräknar modellens prestanda på testdatasetet. Nu kommer R2 visa att modellens prediktiva förmåga har försämrats. En stor försämring betyder att variabeln som blandades om var betydelsefull. Övriga tio variabler ges samma behandling, vilket resulterar i elva mätvärden, en per variabel, som i detta exempel visar deras betydelse för att prediktera pris. Vanligen görs den slumpmässiga omblandningen av en variabel flera gånger, vilket kan ge något olika resultat, där medelvärde och standardavvikelse ger bra bild av variablerna betydelse i modellen.
Partiella beroenden, partial dependence plot
Nästa metod för att göra den svarta lådan mer transparent försöker visa hur en förändring av en indatavariabel påverkar modellens prediktion. Likheter finns med hur koefficienterna i en linjär regression kan tolkas. Om allt annat är lika, om x förändras, vad händer då med y?
Antag ånyo att en regressionsmodell, valfri ML-algoritm eftersom metoden är modellagnostisk, förklarar pris mer tre variabler. Antag vidare att datasetet består av 50 000 observationer, vilket betyder 50 000 prisobservationer med tillhörande variabler som redovisar mätvärden för tillgänglighet, service och byggår. Första steget är att träna modellen med vårt dataset. Nästa steg är att iterativt prediktera pris med modellen för alla observationer i datasetet, men vi låter en variabel i taget anta alla värden som existerar i datsetet samtidigt som de övriga variablerna är låsta så som de ser ut i datsetet. Variabeln byggår kan till exempel variera i intervall från 1850 till 2023. För var och en av de 50 000 observationerna tillåts byggår variera i detta intervall. Resultatet är 50 000 linjer som beskriver variablernas partiella beroenden. Figuren som redovisar detta kallas för en partial dependence plot. Medelvärdet av dessa linjer är modellens partiella beroende för den undersökta variabeln. Metoden är beräkningsintensiv, men det finns smarta implementeringar som ger rimliga beräkningstider även för stora dataset.
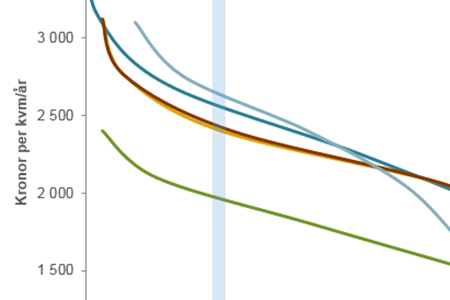
Figuren visar det partiella beroendet mellan byggår och pris. Bilden stämmer väl med intuitionen. De minst attraktiva bostäderna har byggår från 1960 till 1980 och de högst är priserna är enligt grafen för sekelskiftes- och nyproduktionsbostäder.
Eftersom metoden är modellagnostisk kan den även tillämpas på en vanlig multipel linjär regression. Plottas det partiella sambandet för en linjär regressionsmodell går det att visa att linjes lutning, dess derivata, är nästan exakt koefficienten för variabeln i modellen.

Hallucinationer
Det är välkänt att generativ AI inte alltid är pålitlig. Ibland ges svar som presenteras som fakta men som uppenbarligen inte är sant. Fenomenet har kallats för hallucination.
Begreppet bidrar till att förmänskliga generativa AI-modeller, vilket kan ge felaktiga associationer. Enkelt förklarat är de märkliga resultaten orsakade av otillräckligt underlag för att träna modellen, mönster kan inte identifieras och ett nonsensresultat produceras. För regressionsmodeller som utvecklats med maskininlärning finns liknande problem. En prediktion med indata som ligger utanför det intervall som modellen har tränats med kan vara opålitligt. Vissa algoritmer fungerar mycket dåligt utanför kända intervall, andra något bättre. Det är alltså viktigt att känna till vilka scenarier som en modell hanterar bra och mindre bra eller till och med dåligt. Regressionsmodellen som predikterar pris i exemplet ovan, bör till exempel inte användas för att prediktera pris för bostäder med byggår efter 2023.
Relaterade uppdrag






















































































































Vill du veta mer om Svarta lådor och hallucinationer?
Vi berättar gärna mer om vårt affärsområde Svarta lådor och hallucinationer. Maila direkt via länken till höger.